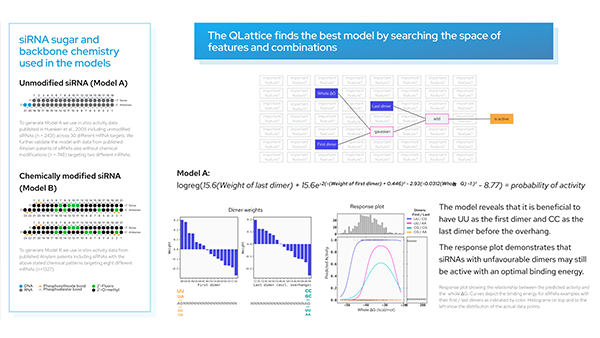
When you think about AI, what do you think about?
Do you think about machine learning? How about all the research put into self-driving cars or image recognition or natural language processing?

The first self-driving car?
At what point do you start thinking about creative thinking machines that can learn and adapt to their environment?
There’s a particular reason why we at Abzu have found it unsatisfying to refer to “machine learning” as “AI”:
There’s a lot of human interaction.
We, humans, choose the hyperparameters, plan the architecture, and experiment with different activation functions.
Of course, machine learning techniques and algorithms have proven to be very successful in the past decade, and we are likely to see more breakthroughs in these areas in the next decade.
However, this does not feel like the right way to create AI. It feels more like statistics on steroids.
How can we move in the right direction again? One of the first steps would be to reduce the amount of human interaction that goes on. Instead of a human designing the architecture, what if we let the machine find the correct model?
The idea at hand is analogous to an evolutionary process, where the models represent a species population and the data represents the environment to which they must adapt to survive.

Models… Uh… find a way.
How does this work? First, the initial population of models is randomly generated. Second, the data is run through each model and only those whose characteristics follow the criteria for selection, e.g., minimum loss, can pass them on to the next generation. Then, a new sample of models is drawn and their architectures are more likely to be similar to the fittest of the previous generation. A new selection round begins, and the process continues.
After running through the procedure described above, the surviving models should be the best fit to the data. In summary: the final models were the result of a process with random initial conditions, whose evolution was shaped by the data itself.
At this point, you may be thinking: “well, a model that not only changes its parameters to fit data, but its whole architecture! That is certainly interesting!” Well then… Rejoice! This technology exists and it will be the subject of the next paragraphs. This new step on the AI path is the QLattice.
The QLattice.
As a first step, one must set the rules of the game: define the independent variables and the target output. Yes, the QLattice works with supervised learning. The input and output variables are, respectively, the entry and exit points of the QLattice. They are called registers. Once these are set, a collection of possible models can be extracted from the QLattice: they arise from the innumerous paths the independent variables can take to reach the final target. Under the evolutionary analogy, said collection corresponds to the initial population of individuals. In technical terms, a population is called QGraph.
As the name may indicate, the models pertaining to a QGraph are, themselves, graphs. In the current context, these are sets of nodes connected by edges. Akin to a neural network, the nodes have activation functions and the edges carry weights. After calculating forward propagation and gradient descent, the fittest graphs have the smallest loss values among the others in the QGraph.
The QLattice can now be updated with the best fit graph. As a consequence, the next generation, or QGraph, will be more likely to have graphs that follow a similar architecture. The steps of model selection described above are then repeated and this loop of getting a QGraph, fitting, and updating goes on until a desired outcome is reached.
In a practical summary:
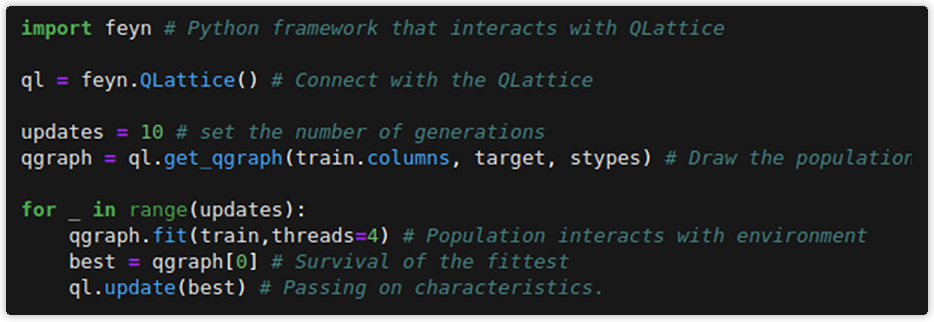
Training loop in Python code.
And a simple graph that could be a best fit to data is given below:
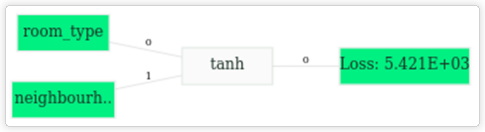
Simple graph.
Where “room_type” and “neighbourhood” are features from the chosen data set.
What is the result of this process? Models are created more organically and so we are a small step closer to an actual thinking machine that adapts and evolves to their environment.
If you want to give this a try then you can play around free for noncommercial use.