Data preprocessing is a necessary, but time-consuming, part of any data scientist’s workflow. In this article, I’ll talk about our product at Abzu®, the QLattice and the python library, Feyn, and how it can help you spend less time on data preprocessing for machine learning tasks – and give you a few bonuses on the way.
We’re going to go through a data example using a pizza menu I’ve spent all my spare time digitizing for exactly this purpose. You can find the dataset as well as this notebook here on GitHub.
I’m gonna do a short recap on the QLattice, but otherwise assume that you’ve read or will read this for more information.
TLDR; on the QLattice.
The QLattice (short for Quantum Lattice) is an evolutionary machine learning approach developed by Abzu that lets you find the best models for your data problem. This is done by continually updating the QLattice with your best model structures to narrow the search field to come up with better models as you have them compete with each other.
Training works by asking your QLattice to generate thousands of graphs containing mappings between your inputs and output, training them, and updating your QLattice to get even more, and better, graphs.
This is done using a python library called Feyn [/ˈfaɪn/], which you can pip install on Windows, OS X, or Linux.
If you want to follow along, you can learn about free community QLattices here.
Let’s load in the data real quick.
We’re using pandas to load this up real quick from a csv.
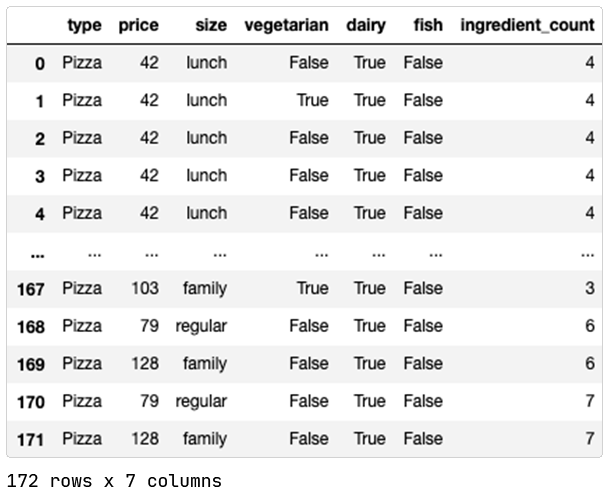
We’ve dropped some unique identifiers to avoid encouraging memorization, and that holds for the comma-separated list of ingredients in the dataset too (since they’re mostly unique per pizza). We have kept tangential information instead. We could do further work to use more of the ingredients feature, but we’ll leave that as an exercise for now as our objective is not training a perfect model.
After loading, admittedly, this dataset is already a lot nicer than what you’d find in the wild, so it contains no NaN or otherwise missing values.
So with that out of the way, let’s take a closer look!
The bare necessities.
This next part, depending on the algorithm, would normally be about data preparation before training, and that’s where Feyn comes to your aid.
With Feyn, we’ve taken a page out of the pythonic stylebook, and one of the core features is the batteries-included approach of just being able to drop in a dataset, and start extracting models. All the rest happens under the hood.
The only thing you need to consider is whether or not your column is:
- Numerical
- Categorical
And that’s it. Let’s take it for a spin!
Connection link established.
Let’s first connect to our QLattice. I’m running this post in our interactive JupyterLab environment, so I don’t need to specify a token. If you were to connect to your own you’d need both a URL and Token to authenticate.
Let’s have a look at our data types, and also present a helper function that creates a dict mapping your categorical input to what we call the ‘categorical’ semantic type. This function just guesses it based off of the pandas datatypes, but you could manually create it as well.
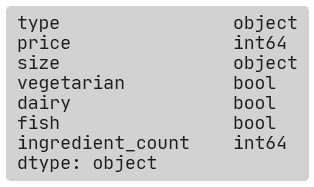
And Bob’s your uncle!
Wait, was that it?
Yeah, that was really it. Now you just need to provide this dict in the stypes parameter when fitting your models.
Notice how we haven’t even fed any data into it yet. So far, we’ve only been working on the conceptual level of the problem domain.
That’s pretty neat!
So let’s train a model using the QLattice.
Let’s just split the dataset into train and test for evaluation.
Next, we’ll run an update loop for our QLattice, training it on our pizza dataset to predict the price. We’re gonna gloss over this, but read the docs if you’re curious for more.
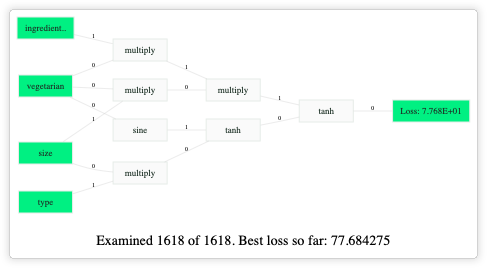
Let’s quickly evaluate the solution.
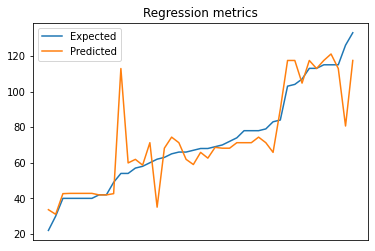
It’s important to stop and check that what we have makes sense, so let’s check out the RMSE on the train and test set. The prices are in DKK.

We see a slight bit of overfitting, but good enough for our purposes. Let’s plot it real quick.
Looking into the semantic types.
I’ve declared a simple function to help us inspect the graphs, but let’s back up first with some theory.
Feyn has two kinds of stypes, the numerical and categorical type.
The numerical semantic type.
The default behaviour in Feyn is standardisation, using something like the MinMaxScaler you might already know and love from sklearn. It works on the input node level, and auto-scales your inputs to be within -1 and 1 based on the minimum and maximum value it sees. The output node has the exact same behaviour, but also ensures that your output is automatically destandardised to your expected values.
Let’s look at the ones from our trained graph:

The first interaction in the graph is ‘ingredient_count’, and as you can read from the state, it has detected the minimum value of 1.0 and the maximum value of 9.

The second interaction is ‘vegetarian’, which is a boolean feature, and Feyn has detected the min value of 0 and max value of 1. So this has just resulted in a recentering around 0.
The categorical semantic type.
So what’s the magic behind the variables? The categorical semantic type is essentially a kind of auto-adapting one-hot encoding. Let’s take an example:
Suppose you have the pizza menu, and you have three types of pizza offers: regular, family, and lunch. A traditional one-hot encoding approach would convert these into three mutually exclusive features: is_regular, is_family, and is_lunch.
What Feyn does is similar, but instead assigns a weight to each category that will be adjusted during training. So when you pass in a pizza that is family-sized, it’ll use the weights for family-sized pizzas, and the same for regular and lunch offers. Unlike one-hot encoding, all of this happens within the same feature node.
Let’s get real:
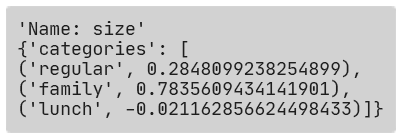
We can see for this interaction that it has learned a weight for each feature value. By looking at this, we can also see which values drive higher separation. For instance, ‘family’ has learned a high weight (close to 1), regular is a bit to the positive side of 0 (the center), and ‘lunch’ has a slight negative weight.
Interpreting this requires you to look at the full graph, but we see clear separation already where we can guess that family and regular drive higher prices than lunch.
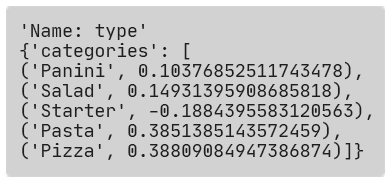
The same as above is experienced on the type, where we can see pizzas and pasta commanding higher separation than salads and paninis, and the starters driving to the negative, gisting at lowering the prediction for price.
So what does this mean?
Hopefully you’ve learned something new on how the semantic types save you time with data preprocessing, and how the categorical semantic type can even help you on the way of getting insights out of your data and models you wouldn’t have seen otherwise.
You’ll also have more insights the next time you order a pizza with three extra servings of cheese and you wonder about the price spike.
If you’re tempted to take a look yourself, head on over here try a QLattice for noncommercial use.